Job Requeue
How to split your neverending job (i.e. Revbayes) into smaller batches to extend the possibilities and enhance performance.
Intro
As we have mentioned in this guide, we have the SLURM scheduler to manage resources. We have partitions with different priority values to help balance resource asks. Your job is directed to one partition or another in terms of the time limit and the type of node that you are asking for. These partitions also imply some other limitations in terms of the number of jobs running or in queue per user at the same time or the total number of processors. You can see some of these limits with the command batchlim. As you could see, these differences are especially notorious with jobs sent to the ondemand partition.
Name Priority GrpTRES MaxTRES MaxWall MaxJobsPU MaxTRESPU MaxSubmit
------------ ---------- ------------- ------------- ----------- --------- ------------- ---
short 50 cpu=2048 50 cpu=2048 100
medium 40 cpu=2048 30 cpu=2048 50
long 30 cpu=8576 cpu=2048 5 cpu=2048 10
requeue 20 cpu=2048 5 cpu=2048 10
ondemand 10 cpu=4288 cpu=1024 2 cpu=1024 10
...
clk_short 50 node=1 06:00:00 200 cpu=960 400
clk_medium 40 node=1 3-00:00:00 200 cpu=960 250
clk_long 30 cpu=1440 node=1 7-00:00:00 60 cpu=360 60
clk_ondemand 10 cpu=720 node=1 42-00:00:00 20 cpu=240 20
...
This method makes use of system signaling, SLURM requeue capability, and application checkpointing to build a solution to this limitation while preserving the balance in the system.
Summary and Generalization
To break your long job into smaller batches you need 3 main tools. You need to catch the SIGTERM signal with the trap command in your submit script, add a requeue option when the program receives the signal, and also, ask the systems department to give requeue capabilities to your job (this step is mandatory to work and it’s not possible to be done by the user itself!) and finally, to manage application checkpointing procedure.
For this template, the variable max_restarts is defined for controlling that your job doesn’t run forever without supervision but you can also define some other criteria to decide if you should do a requeue or not as meeting some convergence criterion.
The next script is a general template that you can adapt to quickly set your job running. You should adapt what you need and add your application lines underneath. If you want to see the process in a real-world example go to the next section [Use case].
#!/bin/bash
##############################################################
## SBATCH directives, modify as needed ##
#SBATCH -t 24:00:00
#SBATCH -C clk #Node type. Leave empty for ilk
#SBATCH -J Rolling
#SBATCH -o /PATH/TO/STDOUT.out
#SBATCH -e /PATH/TO/STDOUT.err
#SBATCH -N 1
#SBATCH --ntasks-per-node=1
#SBATCH -c 10
#SBATCH --mem-per-cpu=3G
#SBATCH --signal=B:SIGTERM@30
##############################################################
## Gather some information from the job and setting limits ##
max_restarts=4 # tweak this number to fit your needs
scontext=$(scontrol show job ${SLURM_JOB_ID})
restarts=$(echo ${scontext} | grep -o 'Restarts=[0-9]*****' | cut -d= -f2)
outfile=$(echo ${scontext} | grep 'StdOut=' | cut -d= -f2)
## ##
##############################################################
## Build a term-handler function to be executed ##
## when the job gets the SIGTERM ##
term_handler()
{
echo "Executing term handler at $(date)"
if [[ $restarts -lt $max_restarts ]];then
# Copy the log file because it will be overwriten
cp -v "${outfile}" "${outfile}.${restarts}"
scontrol requeue ${SLURM_JOB_ID}
exit 0
else
echo "Your job is over the Maximun restarts limit"
exit 1
fi
}
## Call the function when the jobs recieves the SIGTERM ##
trap 'term_handler' SIGTERM
# print some job-information
cat <<EOF
SLURM_JOB_ID: $SLURM_JOB_ID
SLURM_JOB_NAME: $SLURM_JOB_NAME
SLURM_JOB_PARTITION: $SLURM_JOB_PARTITION
SLURM_SUBMIT_HOST: $SLURM_SUBMIT_HOST
Restarts: $restarts
EOF
## ##
##############################################################
## Here begins your actual program ##
## ##
## Modules to load ...
## srun application ...
Use case
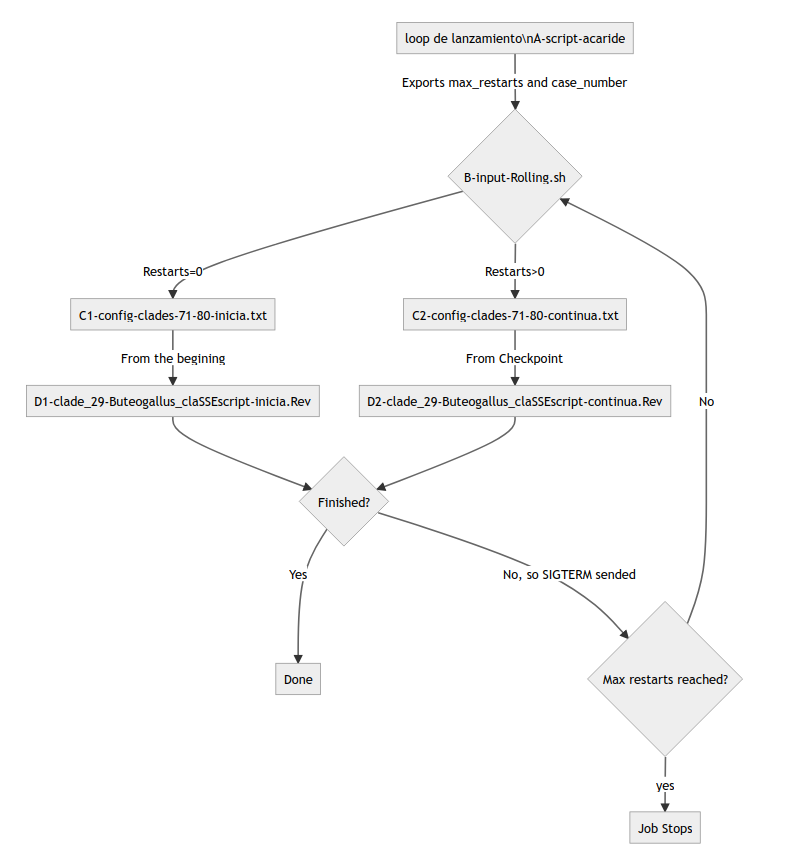
This use case is intended to perform phylogenetic analysis in time-demanding runs. Also, the user has many cases to process completely independent so that can be done separately. The prior workflow is as follows:
Run a script that loops over the total number of cases submitting independent jobs.
Each job reads input of each line of a config.txt file and performs analysis with a time limit of 42 days, so it goes to the ondemand partition/QOS.
The job continues running while it reaches the time limit specified no matter if the convergence criterium is achieved or not.
At the end of the job the convergence is evaluated and wether it could be a successful run or not. If not, the run starts again from the beginning.
As you could see, this method has no guarantee of the correct use of computational resources so we start to look for a new workflow. First of all, let’s see the tools needed.
System signaling
Every process can listen to system signals while is running. Also when a job dies because of time limit, node failure, or some other system event it sends a terminating signal, SIGTERM.
We use the command trap to manage what to do when a signal is cached. So we can use trap "echo I've got a signal" SIGTEM to echo a message when a terminating signal is reached, in other words, when the job is dying.
We build a term handler function to manage these signals more efficiently.
term_handler()
{
echo "Executing term handler at $(date)"
export num_lin # A variable that comes from the previous step
if [[ $restarts -lt $max_restarts ]]; then
# Copy the logfile because will be overwritten by 2nd run
cp -v "${outfile}" "${outfile}.${restarts}"
scontrol requeue ${SLURM_JOB_ID}
exit 0
else
echo "Your job is over the Max Restart Limit"
exit 1
fi
}
And further in that same script:
trap 'term_handler' SIGTERM
With this function, we check if our job is over the maximum prefixed value of restarts, just for the sanity of the system, and if it’s not it does a SLURM requeue.
Note: we can modify at what time from the end of the job the signal is emitted with a sbatch directive #SBATCH --signal=B:SIGTERM@10. In this directive, we tell the job to send a SIGTERM to the .batch job which handles the running application 10 seconds before the job death. Obviously, you should adapt this time to fits your needs. I.e. Your application can perform checkpoints ondemand but it takes 5 min to complete -> #SBATCH --signal=B:SIGTERM@360 send a signal 6 minutes before the time limit is reached.
SLURM Requeue
That SLURM requeue command is performed when the job is about to die. It has some advantages over sending another job, especially in terms of priority conservation. For accounting reasons, it is also better to have that unique job with a unique job id and resource consumption.
For now, the possibility of adding the requeue property to a job is only available to system administrators so we can check if everything is okay with the rolling job before the feature is unlocked. I.e. Are application checkpoints well defined and working properly? Is the maximum number of restarts well-defined?
Once this asking is accepted you are almost done.
Application checkpointing
Your application must handle the checkpointing part itself. The need is to write checkpoints and to be able to restart from that point.
In revbayes, it is done by modifying some part of your .rev file. Let’s see.
DATASET = "clade_29-Buteogallus"
# filepaths
fp = "/PATH/TO/THE/FILES"
in_fp = fp + "data/"
out_fp = fp + "/" + DATASET + "_output/"
check_fp = out_fp + DATASET + ".state"
...
...
# To restart from the checkpoint file uncomment next line
# mymcmc.initializeFromCheckpoint(check_fp)
# To write checkpoints to a checkpoint file. Adjust the checkpoint interval
mymcmc.run(generations=3000, tuningInterval=200, checkpointInterval=5, checkpointFile=check_fp)
How it is implemented now is by having two different .Rev files that act as a launcher and a continuator. This could likely be performed on the same .Rev file. All of this is redirected from a config.txt file with separate lines for each case.
Review of the workflow